Go backward to 5.2 Connection Servers
Go up to 5 Implementation
|
Go backward to 5.2 Connection Servers Go up to 5 Implementation |
|
After a distributed session has been established, the scheduler accepts tasks from the Maple process and schedules these tasks among any node connected to the session. A task is a pair (taskid, exp) where taskid is an integer number identifying the task and exp is a string to be submitted to the Maple process. Initially, the scheduler informs each Maple process about the range of task identifiers it may use for assignment to new tasks such that each node in the system can independently create new tasks.
The following paragraphs sketch the operation of the scheduler; the protocol of interactions between a scheduler and its external application process (e.g. Maple kernel) is formally specified in the appendix.
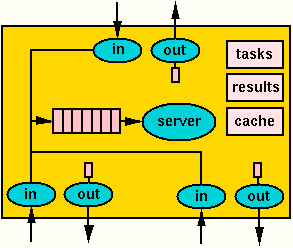
The scheduler is implemented by a number of concurrent threads as shown in Figure 5.3. A central server thread sequentially processes messages that were received from any input channels and put into a central buffer by a thread listening on that channel. The scheduler thread puts every output message into a buffer that is read by a thread writing the message on the corresponding output channel.
An additional watchdog thread in each remote scheduler controls in regular intervals if messages have been received from the local scheduler. If after the last control period no message has been received, the watchdog sends a "ping" message to the local scheduler. If during the next control period no reply has been received, the watchdog assumes that the connection is broken and aborts the external application process and the scheduler. Thus we ensure that failed sessions do not lead to stalled remote processes.
Each scheduler holds a local task queue, a result table, and a result cache. When a new task is created by the external application process, a corresponding "empty" entry is created in the result table (which will be filled by the result the result has been executed). Thus the result of a task is stored on that node of the distributed session where the task has been created; from the identifier of a task, we can uniquely determine the node holding the task and route requests for its result appropriately.
All remote schedulers send the tasks created by the corresponding application processes to the local scheduler; from here they are centrally managed and distributed among all session nodes. Currently a simple load balancing scheme is used where the local scheduler assigns new tasks to remote schedulers until the number of not yet started tasks reaches an upper treshold (specific to the node class) and a remote scheduler asks for new tasks whenever the number of not yet started tasks falls below a lower treshold.
When an application process asks for the result of a task, this request can be locally satisfied if the corresponding scheduler is the holder of the task result. Additionally each scheduler holds a cache of all results that it has "seen" (because the task was executed on this node or, in case of the local scheduler, the task result has passed this node on its way from the node that computed the result to the node that actually holds the result).
If the request of a task result cannot be satisfied (because the result is not yet available or another node holds the task result), the requesting application process receives another task for execution. The Maple kernel implements this request by invoking the server loop recursively and thus starting a new "level" of task execution. If after the completion of this task the requested result is available, this result is delivered. Therefore every Maple kernel (also the kernel connected to the user interface) permanently computes as long as sufficiently many tasks are available.
The execution of dist[process] causes an additional
Maple kernel to be created and attached to some instance of a scheduler. The
new kernel is appropriately initialized (also by executing all commands
previously issued through
dist[all] and reserved for the execution of the denoted
task. After this task has terminated, the process is preserved for later use.
Initially, there exist only connections between the frontend node to each remote node. However, all nodes know of each other, i.e., of a machine address and the number of a port on which a thread is listening for connection requests. When a node needs to send a message to one of its peers, thus a direct connection is established for the message transfer. The connection remains persistent through the rest of the session such that no more startup overhead is involved.
Peer connections have been introduced in version 1.10 of the scheduler;
they can be switched off by the command line option -n.
By default, every transmitted object has to be stored in the memory of the
scheduler process, temporarily (auxiliary objects that are soon reclaimed by
garbage collection) but perhaps also permanently (task results which can be
only cleared by the user command dist[clear]clear). If this becomes a
problem (e.g. because the Java Virtual Machine runs out of memory), the
content of a large message can be automatically evacuated to disk: the message
is read in pieces of fixed size which are written to a temporary file (which
is read again when the message content has to be forwarded to another
process).
Message buffers have been introduced in version 1.10 of the scheduler;
they are disabled by default but can be enabled by the command line option
-b.