Go backward to Distributed Maple
Go up to Top
Go forward to Conclusions
|
Go backward to Distributed Maple Go up to Top Go forward to Conclusions |
|
As discussed in Section *, one of the most time-consuming
components of the CASA function pacPlot is the computation of
multi-variate polynomial resultants. In this section, we are going to describe
the problem, a sequential solution algorithm, a parallel version of this
algorithm, and our implementation of this algorithm in Distributed Maple. We
conclude by listing benchmark results that demonstrate the actual efficiency
of the parallel solution.
Let A=SUMi=0mAi xi and B=SUMi=0nBi xi be non-zero polynomials over an integral domain I, i.e.,
A, B inI[x]The Sylvester matrix of A and B is the m+n by m+n matrix
whose upper part consists of n rows of the coefficients of A and whose lower part consists of m rows of the coefficients of B (all entries not shown are zero). The resultant of A and B is the determinant of this matrix, i.e.,
Am Am-1 ... A0 ... ... ... ... Am Am-1 ... A0 Bn Bn-1 ... B0 ... ... ... ... Bn Bn-1 ... B0
Resultant(A,B) inI.
In the context of the plotting of algebraic curves, we are interested in the special case where A and B are polynomials in r variables over the integers, i.e., given
A,B inZ[x1,...,xr-1][xr]we want to find
Resultant(A,B) inZ[x1,...,xr-1].For plotting algebraic curves in two dimensions, we have to solve this problem for r=2.
Collins [12] describes an efficient sequential algorithm for multivariate polynomial computation based on a modular approach: we use various prime numbers p to map the coefficients of A and B into modular domains Zp = {0,...,p-1}, i.e., we compute polynomials a=Mapp(A), b=Mapp(B) where
a, b inZp[x1,...,xr-1][xr].We may only use primes p such that degree(a)=degree(A) and degree(b) = degree(B) where degree(P) denotes the degree of polynomial P in the main variable. Using modular arithmetic in Zp, we compute the modular resultant c := Resultantp(a, b), i.e.,
c inZp[x1,...,xr-1].We then apply the Chinese Remainder Algorithm to lift the result from Zp to ZP*p, i.e.,
ChineseRemainder(C, c, P, p) inZP*p[x1,...,xr-1]where P is the product of the primes used so far and C is the combination of the corresponding modular resultants:
C inZP[x1,...,xr-1]The algorithm iterates until P exceeds a predetermined bound cb for the size of the coefficients of the resultant and then returns C. The algorithm is sketched below:
C := Resultant(A, B)
m := degree(A); n := degree(B)
cb := CoeffBound(A, B)
C := 0; P := 1
while P <= cb do
p := a new prime number;
if Am mod p != 0 /\ Bn mod p != 0 then
a := Mapp(A); b := Mapp(B)
c := Resultantp(a, b)
C := ChineseRemainder(C, c, P, p)
P := P*p
end
end
end Resultant
Various parallel versions of the modular algorithm have been investigated and implemented on shared memory machines [13] and on workstation networks [14]. Their common idea is to compute the resultants in the individual modular domains in parallel; they differ in their approaches to efficiently combine the modular resultants to yield the integer resultant. We apply the idea used by [13] where the sequential structure of the combination phase is maintained but the individual coefficients of the resultant are computed in parallel.
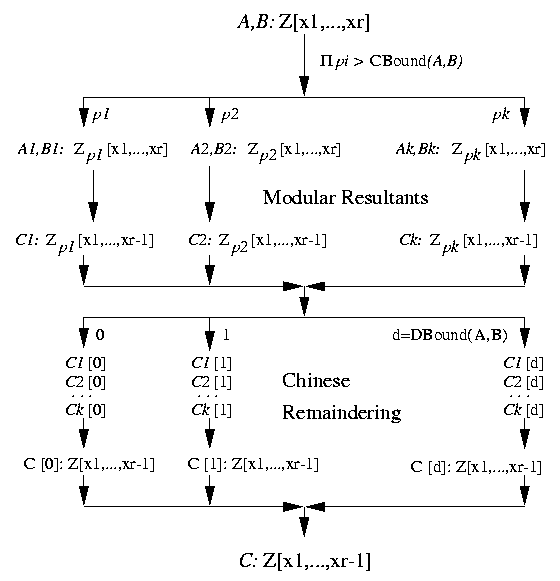
The parallel algorithm starts for each modular domain a task that maps A and B into this domain and computes the coefficients of the modular resultant (up to a predetermined degree bound db). The task results are collected and for each resultant coefficient a task is started that iteratively combines the corresponding modular coefficients. The task results are collected to build the overall result.
C := ResultantParallel(A, B)The structure of the algorithm is illustrated in Figure *.
m := degree(A); n := degree(B)
cb := CoeffBound(A, B)
db := DegreeBound(A, B)
C := 0; P := 1; T := [ ]; L := [ ]
while P <= cb do
p := a new prime number;
if Am mod p != 0 /\ Bn mod p != 0 then
t := start(ResultantModular, p, db, A, B)
P := P*p; T := T || [t]; L := L || [p]
end
end
R := WaitForAll(T)
T := [ ]
for i in[0 ...db] do
t := start(ChineseRemainderCoeff, L,
[R[j]i | j in[1...length(R)])
T := T || [t]
end
C := WaitForAll(T)
end ResultantParallel
We have implemented above algorithm for r=2 using
the Distributed Maple constructs dist[start] and
dist[wait]. Furthermore, we have replaced the Maple function
resultant/bivariate (which is called by Maple
for computing the resultants of bivariate polynomials) by a version that uses
our parallel implementation if the degrees of both input polynomials in the
main variable are are greater than five and the degree of one input polynomial
is greater than ten. All other cases are still solved by sequential methods.
The implementation differs from above algorithm in that each task computes multiple modular resultants respectively multiple coefficients of the integer resultant. By adjusting the number of elements computed by a task we can effectively control its grain size.
For estimating the execution time of a "ResultantModular" task we use the complexity bound [12]
where degreei(P) denotes the degree of P in the i-th variable. Based on this bound (multiplied by an experimentally determined constant that represents the processor speed) our implementation adjusts the number of modular images per task such that each task is expected to execute roughly 10 seconds. Smaller grain sizes unduly increase the execution overhead while larger grain sizes may cause significant load imbalances.
(1+max(degreer(A), degreer(B))) *PRODi=1r(1+max(degreei(A), degreei(B))) *SUMi=1r(1+max(degreei(A), degreei(B)))
We also adjust the number of coefficients computed per "ChineseRemainderCoeff" task such that it processes for any input a constant number of modular coefficients. We have experimentally determined a value for this constant (1800) such that the execution time of a the task roughly matches the execution time of a "ResultantModular" task.
The first four modular resultants are actually computed sequentially in order to derive an improved value for the degree bound such that fewer coefficients have to be considered in the rest of the algorithm.
We have benchmarked our implementation with numerous inputs and machine configurations; the results of some of these experiments are shown below. The system environment in which the parallel program has been executed consists of (various subsets of) the following machines:
We have applied the CASA function pacPlot to four algebraic curves
represented by the randomly generated bivariate polynomials listed in
Figure * and have measured the execution times of the corresponding
resultant computations (using the sequential resultant function provided by
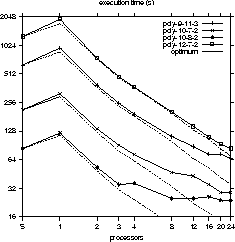
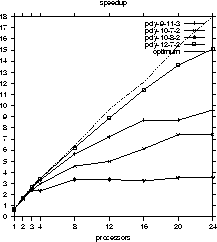
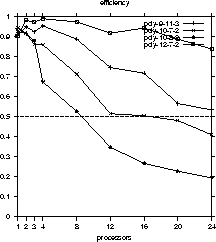
Maple and our parallel version). The results are listed in Figure *
and visualized in Figure *.
Name Tot.Deg. Value 9-11-3 14 23x4y8-17x6y6+22x8+84x7y7+20x4y6-49x3y8-80x4y2-5x3y-92x3y2-47y8+5xy5 10-7-2 13 55x8y2+66x9y4+27y3+31x2y5-75x2y6-70y8-97x2y9 10-8-2 18 -22x9y9-26x2y5+85x8y-50x2y6-74x6y4-31x8y7-172x7y7 12-7-2 20 99xy9-12x6y2-26x2y11-47x8y11-61x5y8-90x9y11+94x2y
Processors Performance Time (s) 9-11-3 10-7-2 10-8-2 12-7-2 Sequential 1 634 214 84 1267 1 0.73 958 317 122 1920 2 1.73 386 135 53 746 3 2.73 251 91 35 477 4 3.46 192 72 36 370 8 6.48 112 47 25 204 12 9.66 88 43 25 143 16 12.1 73 35 26 111 20 15.34 73 29 24 93 24 17.99 66 29 24 84
The largest speedup was 15 (compared to a sequential execution time of 1267 seconds) with 24 processors, which corresponds to an efficiency of more than 80% (considering the total system performance). All four examples achieved an efficiency of at least 50% with 8 processors, three examples achieved an efficiency of at least 50% with 20 processors. The example that ran shortest (sequential execution time of 84 seconds) achieved a maximum speedup of 3.5 with 8 processors (50% efficiency).
Machines
Tasks
Utilization
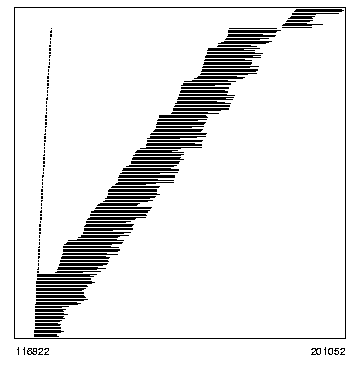
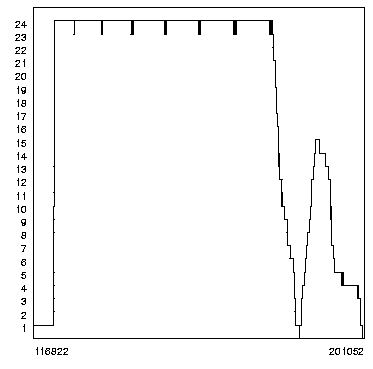
The visualization of a program run shown in Figure * (curve
12-7-2, 24 processors) gives an impression of the dynamic behavior of the
algorithm (the diagrams have been produced from a trace file generated by the
scheduler on issuing the Maple command dist[trace]). The left figure
shows the load of each machine, the middle figure displays all tasks, and the
right figure shows the machine utilization during the computation of the
resultant.
We see that a very short initial phase where only one machine is active (the sequential computation of four modular resultants) is followed by a long phase where all machines are active computing modular resultants in parallel. This phase is followed by a shorter phase where only part of the machines are active combining the coefficients of the modular resultants by the Chinese Remainder Algorithm. Since tasks have been calibrated to run about 10 seconds, there is not sufficiently much parallelism to keep all machines active in this phase.
The fact that some of the Chinese Remainder tasks seem to execute significantly longer than other tasks can be attributed to the fact that exactly these tasks are on Linux PCs: while the raw (integer) processing power of these machines is larger than those of all other machines, their communication bandwidth (external sockets and/or internal pipes) is apparently much lower. Since the Chinese Remaindering tasks receive very large input arguments, they start execution on these PCs later than on other machines and/or need more time to transfer their results. This is also the reason why we choose to run the initial Maple kernel of a Distributed Maple session on a (otherwise slower) Silicon Graphics workstation; this gives much better overall speedups. We are currently investigating whether the installation of newer versions of the Linux operating system kernel may help to overcome this communication bottleneck.
It is interesting to note that our implementation is based on parallelization constructs that correspond to those of the parallel computer algebra library PACLIB where a similar parallel version of the modular resultant algorithm was implemented in C [13]. Likewise this parallel algorithm was implemented in the para-functional language pD which was compiled to C code that used the PACLIB runtime system [5]. The PACLIB implementation on a shared memory multiprocessor (16 Intel386 at 20 Mhz) achieved a speedup of 11.5 for a problem whose sequential execution time was 180 seconds [13]. The pD implementation achieved a speedup of 11.5 for a problem whose execution time took 160 seconds.
We may compare these results with the resultant computation that arises in the plotting of curve 10-7-2 where the sequential Maple call takes 214 seconds and the parallel implementation in Distributed Maple on a heterogeneous computer network achieves a speedup of 8 with 16 processors and of 10 with 24 processors, respectively. We are not aware of any other reports in literature on speedups gained by parallel resultant computation in distributed environments.