


Go backward to SIMD Hypercube Matrix Multiplication
Go up to Top
Go forward to Ring Algorithm
|
Go backward to SIMD Hypercube Matrix Multiplication Go up to Top Go forward to Ring Algorithm |
|
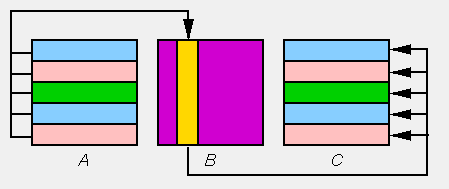
A[i] on every processor P[i].
P[i] do:
for j=0 to N-1 ReceiveB[j]from rootC[i][j]=A[i]*B[j]
C[i]
Broadcasting of each B[j]
->
Step 2 takes O(N logN) time.