This chapter describes the compiler optimization facilities and their benefits, and explains the major optimizing techniques. This chapter includes the following topics:
“Optimization Overview”, provides an overview of optimization benefits and debugging.
“Performance Tuning with Interprocedural Analysis (IPA)”, describes performance tuning with interprocedural analysis.
“Controlling Loop Nest Optimizations (LNO)”, discusses ways of controlling loop nest optimizations.
“Controlling Floating-Point Optimization”, explains methods of controlling floating-point optimization.
“Controlling Other Optimizations with the -OPT Option ” describes how to control miscellaneous optimizations.
“Controlling Execution Frequency” describes how to control execution frequency.
“The Code Generator ”, describes the code generator.
“Reordering Code Regions”, describes methods of optimizing the location of code regions within your program
???, lists programming hints for improving optimization
| Note: Please see the Release Notes and man pages for your compiler for a complete list of options that you can use to optimize and tune your program. |
See your compiler manual for information about the optional parallelizer, apo, and the OpenMP directives and routines for a method of using a portable method to code parallelization into your program. You can find additional information about optimization in the MIPSpro 64-Bit Porting and Transition Guide. For information about writing code for 64-bit programs, see Chapter 5, “Coding for 64-Bit Programs”. For information about porting code to -n32 and -64, see Chapter 6, “Porting Code to N32 and 64-Bit SGI Systems”.
The primary benefits of optimization are faster running programs and often smaller object code size. However, the optimizer can also speed up development time. For example, you can reduce coding time by leaving it up to the optimizer to relate programming details to execution time efficiency. You can focus on the more crucial global structure of your program.
Optimize your program only when it is fully developed and debugged. To debug a program, you can use the -g option. Note that you can also use -DEBUG: options to debug run-time code and generate compile, link, and run-time warning messages.
Debug a program before optimizing it, because the optimizer may move operations around so that the object code does not correspond in an obvious way to the source code. These changed sequences of code can create confusion when using a debugger. For information on the debugger, see dbx User's Guide and ProDev WorkShop: Debugger User's Guide.
The compiler optimization options -O0 through -O3 determine the optimization level to be applied to your program. The -O0 option applies no optimizations, and the -O3 option performs the most aggressive optimizations. See your compiler manual and man page for more information.
Interprocedural Analysis (IPA) performs program optimizations that can only be done in the presence of the whole program. Some of the optimizations it performs also allow downstream phases to perform better code transformations.
| Note: If you are using the automatic parallelizer (-apo), run it after IPA. If you apply parallelization to subroutines in separate modules, and then apply inlining to those modules using -IPA, you inline parallelized code into a main routine that is not compiled to initialize parallel execution. Therefore, you must use the parallelizer when compiling the main module as well as any submodules. |
Currently IPA optimizes code by performing the following functions:
Procedure inlining
Interprocedural constant propagation
Dead function elimination
Identification of global constants
Dead variable elimination
PIC optimization
Automatic selection of candidates for the gp-relative area (autognum)
Dead call elimination
Automatic internal padding of COMMON arrays in Fortran
Interprocedural alias analysis
Figure 4-1, shows the interprocedural analysis and interprocedural optimization phase of the compilation process.
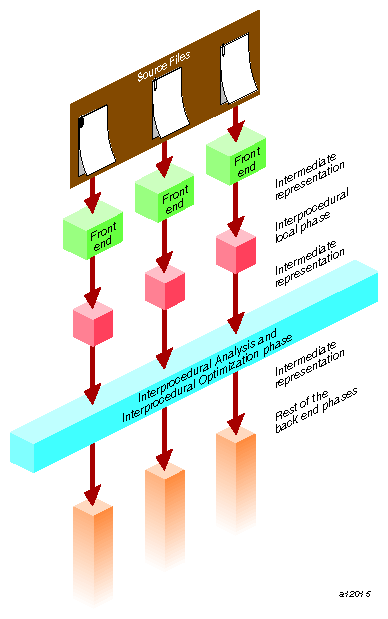
Typically, you invoke IPA with the -IPA: option group to f77, f90, cc, CC, and ld. Its inlining decisions are also controlled by the -INLINE: option group. Up-to-date information on IPA and its options is in the ipa(5) man page.
This section covers some IPA options including:
IPA performs across and within file inlining. A default inlining heuristic determines which calls to inline.
Your code may benefit from inlining for the following reasons:
Inlining exposes a larger context to the scalar and loop-nest optimizers, thereby allowing more optimizations to occur.
Inlining eliminates overhead resulting from the call (for example, register save and restore, the call and return instructions, and so forth). Instances occur, however, when inlining may hurt run-time performance due to increased demand for registers, or compile-time performance due to code expansion. Hence extensive inlining is not always useful. You must select callsites for inlining based on certain criteria such as frequency of execution and size of the called procedure. Often it is not possible to get an accurate determination of frequency information based on compile-time analysis. As a result, inlining decisions may benefit from generating feedback and providing the feedback file to IPA. The inlining heuristic will perform better since it is able to take advantage of the available frequency information in its inlining decision.
You may wish to select certain procedures to be inlined or not to be inlined by using the inlining options.
| Note: You can use the inline keyword and pragmas in C++ or C to specifically identify routines to call sites to inline. The inliner's heuristics decides whether to inline any cases not covered by the -INLINE options. |
In all cases, once a call is selected for inlining, a number of tests are applied to verify its suitability. These tests may prevent its inlining regardless of user specification: for instance, if the callee is a C varargs routine, or parameter types do not match.
The -INLINE:none and -INLINE:all Options
Changes the default inlining heuristic.
The -INLINE:all option. Attempts to inline all routines that are not excluded by a never option or a routine pragma suppressing inlining, either for the routine or for a specific callsite.
The -INLINE:none option. Does not attempt to inline any routines that are not specified by a must option or a pragma requesting inlining, either for the routine or for a specific callsite.
If you specify both all and none, none is ignored with a warning.
The -INLINE:must and -INLINE:never Options
The -INLINE:must=routine_name<,routine_name>* option. Attempts to inline the specified routines at call sites not marked by inlining pragmas, but does not inline if varargs or similar complications prevent it. It observes site inlining pragmas.
Equivalently, you can mark a routine definition with a pragma requesting inlining.
The -INLINE:never=routine_name<,routine_name>* option. Does not inline the specified routines at call sites not marked by inlining pragmas; it observes site inlining pragmas.

Note: For C++, you must provide mangled routine names. The -INLINE:file=< filename> Option
This option invokes the standalone inliner, which provides cross-file inlining. The option -INLINE:file=< filename> searches for routines provided via the -INLINE:must list option in the file specified by the -INLINE:file option. The file provided in this option must be generated using the -IPA -c options. The file generated contains information used to perform the cross-file inlining.
For example, suppose two files exist: foo.f and bar.f.
The file, foo.f, looks like this:
program main ... call bar() end
The file, bar.f, looks like this:
subroutine bar() ... end
To inline bar into main, using the standalone inliner, compile with -IPA and -c options:
% f77 -n32 -IPA -c bar.f
This produces the file, bar.o. To inline bar into foo.f, enter:
% f77 -n32 foo.f -INLINE:must=bar:file=bar.o
Power of two arrays can lead to degenerate behavior on cache-based machines. The IPA phases try, when possible, to pad the leading dimension of arrays to avoid cache conflicts. Several restrictions exist that limit IPA padding of common arrays. If the restrictions are not met, the arrays are not padded. The current restrictions are as follows:
The shape of the common block to which the global array belongs must be consistent across procedures. That is, the declaration of the common block must be the same in every subroutine that declares it.
In the following example, IPA can not pad any of the arrays in the common block because the shape is not consistent.
program main common /a/ x(1024,1024), y(1024, 1024), z(1024,1024) .... .... end subroutine foo common /a/ xx(100,100), yy(1000,1000), zz(1000,1000) .... .... endThe common block variables must not initialize data associated with them. In this example, IPA can not pad any of the arrays in common block /a/:
block data inidata common /a/ x(1024,1024), y(1024,1024), z(1024,1024), b(2) DATA b /0.0, 0.0/ end program main common /a/ x(1024,1024), y(1024,1024), z(1024,1024), b(2) .... .... endThe array to be padded may be passed as a parameter to a routine only if it declared as a one dimensional array, since passing multi-dimensional arrays that may be padded can cause the array to be reshaped in the callee.
Restricted types of equivalences to arrays that may be padded are allowed. Equivalences that do not intersect with any column of the array are allowed. This implies an equivalencing that will not cause the equivalenced array to access invalid locations. In the following example, the arrays in common /a/ will not be padded since z is equivalenced to x(2,1), and hence z(1024) is equivalenced to x(1,2).
program main real z(1024) common /a/ x(1024,1024), y(1024,1024) equivalence (z, x(2,1)) .... .... endThe common block symbol must have an INTERNAL or HIDDEN attribute, which implies that the symbol may not be referenced within a DSO that has been linked with this program.
The common block symbol can not be referenced by regular object files that have been linked with the program.
The optimizations that are performed later in the compiler are often constrained by the possibility that two variable references may be aliased, meaning they may be aliased to the same address. This possibility is increased by calls to procedures that are not visible to the optimizer, and by taking the addresses of variables and saving them for possible use later (for example, in pointers).
Furthermore, the compiler must normally assume that a global (external) datum may have its address taken in another file, or may be referenced or modified by any procedure call. The IPA alias and address-taken analyses are designed to identify the actual global variable addressing and reference behavior so that such worst-case assumptions are not necessary.
This option performs IPA alias analysis. That is, it determines which global variables and formal parameters are referenced or modified by each call, and which global variables are passed to reference formal parameters. This analysis is used for other IPA analyses, including constant propagation and address-taken analysis. This option is ON by default.
This option performs IPA address-taken analysis. That is, it determines which global variables and formal parameters have their addresses taken in ways that may produce aliases. This analysis is used for other IPA analyses, especially constant propagation. Its effectiveness is very limited without -IPA:alias=ON . This option is ON by default.
Numerical programs often spend most of their time executing loops. The loop nest optimizer (LNO) performs high-level loop optimizations that can greatly improve program performance by better exploiting caches and instruction-level parallelism.
This section covers the following topics:
For complete information on options, see the lno(5) man page.
LNO is run by default when you use the -O3 option for all Fortran, C, and C++ programs. LNO is an integrated part of the compiler back end and is not a preprocessor. Therefore, the same optimizations (with the same control options) apply to Fortran, C, and C++ programs. Note that this does not imply that LNO will optimize numeric C++ programs as well as Fortran programs. C and C++ programs often include features that make them inherently harder to optimize than Fortran programs.
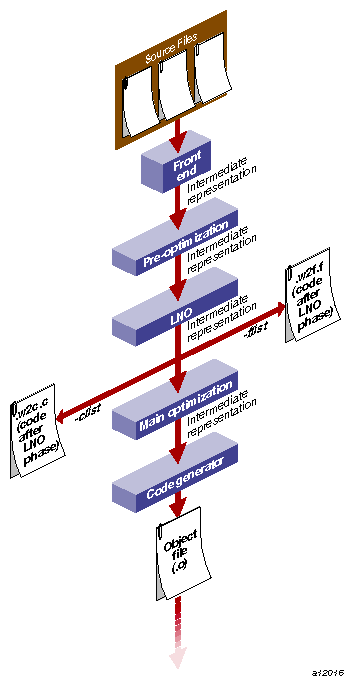
After LNO performs high-level transformations, it may be desirable to view the transformed code in the original source language. Two translators that are integrated into the back end translate the compiler internal code representation back into the original source language after the LNO transformation (and IPA inlining). You can invoke either one of these translators by using the Fortran option -FLIST:=on or the cc option -CLIST:=on. For example, f77 -O3 -FLIST:=on x.f creates an a.out as well as a Fortran file x.w2f.f. The .w2f.f file is a readable file, and it is usually a compilable SGI Fortran representation of the original program after the LNO phase (see Figure 4-2). LNO is not a preprocessor, which means that recompiling the .w2f.f file directly may result in an executable that is different from the original compilation of the .f file.
Use the -CLIST:=on option to cc to translate compiler internal code to C. No translator exists to translate compiler internal code to C++. When the original source language is C++, the generated C code may not be compilable.
This section describes some important optimizations performed by LNO. For a complete listing, see your compiler's man page. Optimizations include:
The order of loops in a nest can affect the number of cache misses, the number of instructions in the inner loop, and the ability to schedule an inner loop. Consider the following loop nest example.
do i
do j
do k
a(j,k) = a(j,k) + b(i,k) |
As written, the loop suffers from several possible performance problems. First, each iteration of the k loop requires two loads and one store. Second, if the loop bounds are sufficiently large, every memory reference will result in a cache miss.
Interchanging the loops improves performance.
do k
do j
do i
a(j,k) = a(j,k) + b(i,k) |
Since a(j,k) is loop invariant, only one load is needed in every iteration. Also, b(i,k) is “stride-1,” successive loads of b(i,k) come from successive memory locations. Since each cache miss brings in a contiguous cache line of data, typically 4-16 elements, stride-1 references incur a cache miss every 4-16 iterations. In contrast, the references in the original loop are not in stride-1 order. Each iteration of the inner loop causes two cache misses; one for a(j,k) and one for b(i,k).
In a real loop, different factors may affect different loop ordering. For example, choosing i for the inner loop may improve cache behavior while choosing j may eliminate a recurrence. LNO uses a performance model that considers these factors. It then orders the loops to minimize the overall execution time estimate.
Cache blocking and outer loop unrolling are two closely related optimizations used to improve cache reuse, register reuse, and minimize recurrences. Consider matrix multiplication in the following example.
do i=1,10000
do j=1,10000
do k=1,10000
c(i,j) = c(i,j) + a(i,k)*b(k,j) |
Given the original loop ordering, each iteration of the inner loop requires two loads. The compiler uses loop unrolling, that is, register blocking, to minimize the number of loads.
do i=1,10000
do j=1,10000,2
do k=1,10000
c(i,j) = c(i,j) + a(i,k)*b(k,j)
c(i,j+1) = c(i,j+1) + a(i,k)*b(k,j+1) |
Storing the value of a(i,k) in a register avoids the second load of a(i,k). Now the inner loop only requires three loads for two iterations. Unrolling the j loop even further, or unrolling the i loop as well, further decrease the amount of loads required. How much is the ideal amount to unroll? Unrolling more decreases the amount of loads but not the amount of floating point operations. At some point, the execution time of each iteration is limited by the floating point operations. There is no point in unrolling further. LNO uses its performance model to choose a set of unrolling factors that minimizes the overall execution time estimate.
Given the original matrix multiply loop, each iteration of the i loop reuses the entire b matrix. However, with sufficiently large loop limits, the matrix b will not remain in the cache across iterations of the i loop. Thus in each iteration, you have to bring the entire matrix into the cache. You can “cache block” the loop to improve cache behavior.
do tilej=1,10000,Bj
do tilek=1,10000,Bk
do i=1,10000
do j=tilej,MIN(tilej+Bj-1,10000)
do k=tilek,MIN(tilek+Bk-1,10000)
c(i,j) = c(i,j) + a(i,k)*b(k,j) |
By appropriately choosing Bi and Bk, b remains in the cache across iterations of i, and the total number of cache misses is greatly reduced.
LNO automatically caches tile loops with block sizes appropriate for the target machine. When compiling for an SGI R8000, LNO uses a single level of blocking. When compiling for an SGI systems (such as R4000, R5000, R10000, or R12000) that contain multi-level caches, LNO uses multiple levels of blocking where appropriate.
LNO attempts to fuse multiple loop nests to improve cache behavior, to lower the number of memory references, and to enable other optimizations. Consider the following example.
do i=1,n
do j=1,n
a(i,j) = b(i,j) + b(i,j-1) + b(i,j+1)
do i=1,n
do j=1,n
b(i,j) = a(i,j) + a(i,j-1) + a(i,j+1) |
In each loop, you need to do one store and one load in every iteration (the remaining loads are eliminated by the software pipeliner). If n is sufficiently large, in each loop you need to bring the entire a and b matrices into the cache.
LNO fuses the two nests and creates the following single nest:
do i=1,n
a(i,1) = b(i,0) + b(i,1) + b(i,2)
do j=2,n
a(i,j) = b(i,j) + b(i,j-1) + b(i,j+1)
b(i,j-1) = a(i,j-2) + a(i,j-1) + a(i,j)
end do
b(i,n) = a(i,n-1) + a(i,n) + a(i,n+1)
end do |
Fusing the loops eliminates half of the cache misses and half of the memory references. Fusion can also enable other optimizations. Consider the following example:
do i
do j1
S1
end do
do j2
S2
end do
end do |
By fusing the two inner loops, other transformations are enabled such as loop interchange and cache blocking.
do j
do i
S1
S2
end do
end do |
As an enabling transformation, LNO always tries to use loop fusion (or fission, discussed in the following subsection) to create larger perfectly nested loops. In other cases, LNO decides whether or not to fuse two loops by using a heuristic based on loop sizes and the number of variables common to both loops.
To fuse aggressively, use -LNO:fusion=2.
The opposite of fusing loops is distributing loops into multiple pieces, or loop fission. As with fusion, fission is useful as an enabling transformation. Consider this example again:
do i
do j1
S1
end do
do j2
S2
end do
end do |
Using loop fission, as shown in the following example, also enables loop interchange and blocking.
do i1
do j1
S1
end do
end do
do i2
do j2
S2
end do
end do |
Loop fission is also useful to reduce register pressure in large inner loops. LNO uses a model to estimate whether or not an inner loop is suffering from register pressure. If it decides that register pressure is a problem, fission is attempted. LNO uses a heuristic to decide on how to divide the statements among the resultant loops.
Loop fission can potentially lead to the introduction of temporary arrays. Consider the following loop.
do i=1,n
s = ..
.. = s
end do |
If you want to split the loop so that the two statements are in different loops, you need to scalar expand s.
do i=1,n
tmp_s(i) = ..
end do
do i=1,n
.. = tmp_s(i)
end do |
Space for tmp_s is allocated on the stack to minimize allocation time. If n is very large, scalar expansion can lead to increased memory usage, so the compiler blocks scalar expanded loops. Consider the following example:
do se_tile=1,n,b
do i=se_tile,MIN(se_tile+b-1,n)
tmp_s(i) = ..
end do
do i=se_tile,MIN(se_tile+b-1,n)
.. = tmp_s(i)
end do
end do |
Related to loop fission is vectorization of intrinsics. The SGI math libraries support vector versions of many intrinsic functions that are faster than the regular versions. That is, it is faster, per element, to compute n cosines than to compute a single cosine. LNO attempts to split vectorizable intrinsics into their own loops. If successful, each such loop is collapsed into a single call to the corresponding vector intrinsic.
The MIPS IV instruction set supports a data prefetch instruction that initiates a fetch of the specified data item into the cache. By prefetching a likely cache miss sufficiently ahead of the actual reference, you can increase the tolerance for cache misses. In programs limited by memory latency, prefetching can change the bottleneck from hardware latency time to the hardware bandwidth. By default, prefetching is enabled at -O3 for the R10000.
LNO runs a pass that estimates which references will be cache misses and inserts prefetches for those misses. Based on the miss latency, the code generator later schedules the prefetches ahead of their corresponding references.
By default, for misses in the primary cache, the code generator moves loads early in the schedule ahead of their use, exploiting the out-of-order execution feature of the R10000 to hide the latency of the primary miss. For misses in the secondary cache, explicit prefetch instructions are generated.
Prefetching is limited to array references in well behaved loops. As loop bounds are frequently unknown at compile time, it is usually not possible to know for certain whether a reference will miss. The algorithm therefore uses heuristics to guess.
Prefetching can improve performance in compute-intensive operations where data is too large to fit in the cache. Conversely, prefetching will not help performance in a memory-bound loop where data fits in the cache.
Software pipelining attempts to improve performance by executing statements from multiple iterations of a loop in parallel. This is difficult when loops contain conditional statements. Consider the following example:
do i = 1,n
if (t(i) .gt. 0.0) then
a(i) = 2.0*b(i-1)
end do
end do |
Ignoring the if statement, software pipelining may move up the load of b(i-1), effectively executing it in parallel with earlier iterations of the multiply. Given the conditional, this is not strictly possible. The code generator will often if convert such loops, essentially executing the body of the if on every iteration. The if conversion does not work well when the if is frequently not taken. An alternative is to gather-scatter the loop, so the loop is divided as follows:
inc = 0 do i = 1,n
tmp(inc) = i
if (t(i) .gt. 0.0) then
inc = inc + 1
end do
end do
do i = 1,inc
a(tmp(i)) = 2.0*b((tmp(i)-1)
end do |
The code generator will if convert the first loop; however, no need exists to if convert the second one. The second loop can be effectively software pipelined without having to execute unnecessary multiplies.
The lno(5) man page describes the compiler options for LNO. Specifically, topics include:
Controlling LNO Optimization Levels (described below)
Controlling Fission and Fusion (described below)
Controlling Gather-Scatter
Controlling Cache Parameters
Controlling Permutation Transformations and Cache Optimization
Controlling Prefetch
All of the LNO optimizations are on by default when you use the -O3 compiler option. To turn off LNO at -O3, use -LNO:opt=0. If you want direct control, you can specify options and pragmas to turn on and off optimizations that you require.
The options -r5000, -r8000, -r10000, and -r12000 set a series of default cache characteristics. To override a default setting, use one or more of the options below.
To define a cache entirely, you must specify all options immediately following the -LNO:cache_size option. For example, if the processor is an R4000 (r4k), which has no secondary cache, then specifying -LNO:cache_size2=4m is not valid unless you supply the options necessary to specify the other characteristics of the cache. (Setting -LNO:cache_size2=0 is adequate to turn off the second level cache; you do not have to specify other second-level parameters.) Options are available for third and fourth level caches. Currently none of the SGI machines have such caches. However, you can also use those options to block other levels of the memory hierarchy.
For example, on a machine with 128 Mbytes of main memory, you can block for it by using parameters, for example, -LNO:cs3=128M:ls3=... . In this case, assoc3 is ignored and does not have to be specified. Instead, you must specify is_mem3.., since virtual memory is fully associative.
Fortran directives and C and C++ pragmas enable, disable, or modify a feature of the compiler. This section uses the term pragma when describing either a pragma or a directive.
Pragmas within a procedure apply only to that particular procedure, and revert to the default values upon the end of the procedure. Pragmas that occur outside of a procedure alter the default value, and therefore apply to the rest of the file from that point on, until overridden by a subsequent pragma.
By default, pragmas within a file override the command-line options. Use the -LNO:ignore_pragmas option to allow command-line options to override the pragmas in the file.
This section covers:
Fission/Fusion
Blocking and Permutation Transformations
Prefetch
Fill/Align Symbol
Dependence Analysis
See the lno(5) man page, or your compiler manual, for more information on these pragmas and directives.
The following pragmas/directives control fission and fusion.
| C*$* AGGRESSIVE INNER LOOP FISSION , #pragma aggressive inner loop fission | |
Fission inner loops into as many loops as possible. It can only be followed by a inner loop and has no effect if that loop is not inner any more after loop interchange. | |
| C*$* FISSION, #pragma fission, C*$* FISSIONABLE, #pragma fissionable | |
Fission the enclosing n level of loops after this pragma. The default is 1. Performs validity test unless a FISSIONABLE pragma is also specified. Does not reorder statements. | |
| C*$* FUSE, #pragma fuse, C*$* FUSABLE , #pragma fusable | |
Fuse the following loops, which must be immediately adjacent. The default is 2,level. Fusion is attempted on each pair of adjacent loops and the level, by default, is the determined by the maximal perfectly nested loop levels of the fused loops although partial fusion is allowed. Iterations may be peeled as needed during fusion and the limit of this peeling is 5 or the number specified by the -LNO:fusion_peeling_limit option. No fusion is done for non-adjacent outer loops. When the FUSABLE pragma is present, no validity test is done and the fusion is done up to the maximal common levels. | |
| C*$* NO FISSION, #pragma no fission | |
The loop following this pragma should not be fissioned. Its innermost loops, however, are allowed to be fissioned. | |
| C*$* NO FUSION , #pragma no fusion | |
The loop following this pragma should not be fused with other loops. | |
The following pragmas/directives control blocking and permutation transformations.
| C*$* INTERCHANGE, #pragma interchange | |
Loops to be interchanged (in any order) must directly follow this pragma and be perfectly nested one inside the other. If they are not perfectly nested, the compiler may choose to perform loop distribution to make them so, or may choose to ignore the annotation, or even apply imperfect interchange. Attempts to reorder loops so that I is outermost, then J, then K. The compiler may choose to ignore this pragma. | |
| C*$* NO INTERCHANGE, #pragma no interchange | |
Prevent the compiler from involving the loop directly following this pragma in an interchange, or any loop nested within this loop. | |
| C*$* BLOCKING SIZE [(n1,n2)], #pragma blocking size (n1,n2) | |
The loop specified, if it is involved in a blocking for the primary (secondary) cache, will have a block size of n1 {n2}. The compiler tries to include this loop within such a block. If a 0 blocking size is specified, then the loop is not stripped, but the entire loop is inside the block. | |
For example:
subroutine amat(x,y,z,n,m,mm)
real*8 x(100,100), y(100,100), z(100,100)
do k = 1, n
C*$* BLOCKING SIZE 20
do j = 1, m
C*$* BLOCKING SIZE 20
do i = 1, mm
z(i,k) = z(i,k) + x(i,j)*y(j,k)
enddo
enddo
enddo
end |
In this example, the compiler makes 20x20 blocks when blocking. However, the compiler can block the loop nest such that loop k is not included in the tile. If it did not, add the following pragma just before the k loop.
C*$* BLOCKING SIZE (0) |
This pragma suggests that the compiler generates a nest like:
subroutine amat(x,y,z,n,m,mm)
real*8 x(100,100), y(100,100), z(100,100)
do jj = 1, m, 20
do ii = 1, mm, 20
do k = 1, n
do j = jj, MIN(m, jj+19)
do i = ii, MIN(mm, ii+19)
z(i,k) = z(i,k) + x(i,j)*y(j,k)
enddo
enddo
enddo
enddo
enddo
end |
Finally, you can apply a INTERCHANGE pragma to the same nest as a BLOCKING SIZE pragma. The BLOCKING SIZE applies to the loop it directly precedes only, and moves with that loop when an interchange is applied.
For example, the following code:
C*$* UNROLL (2)
DO i = 1, 10
DO j = 1, 10
a(i,j) = a(i,j) + b(i,j)
END DO
END DO |
becomes:
DO i = 1, 10, 2
DO j = 1, 10
a(i,j) = a(i,j) + b(i,j)
a(i+1,j) = a(i+1,j) + b(i+1,j)
END DO
END DO |
and not:
DO i = 1, 10, 2
DO j = 1, 10
a(i,j) = a(i,j) + b(i,j)
END DO
DO j = 1, 10
a(i+1,j) = a(i+1,j) + b(i+1,j)
END DO
END DO |
The UNROLL pragma again is attached to the given loop, so that if an INTERCHANGE is performed, the corresponding loop is still unrolled. That is, the example above is equivalent to:
C*$* INTERCHANGE i,j
DO j = 1, 10
C*$* UNROLL 2
DO i = 1, 10
a(i,j) = a(i,j) + b(i,j)
END DO
END DO |
| C*$* BLOCKABLE(I,J,K), #pragma blockable (i,j,k) | |
The loops I, J and K must be adjacent and nested within each other, although not necessarily perfectly nested. This pragma informs the compiler that these loops may validly be involved in a blocking with each other, even if the compiler considers such a transformation invalid. The loops are also interchangeable and unrollable. This pragma does not tell the compiler which of these transformations to apply. | |
The following pragmas/directives control prefetch operations.
| C*$* PREFETCH, #pragma prefetch | |
Specify prefetching for each level of the cache. Scope: entire function containing the pragma. 0 prefetching off (default for all processors except R10000 and R12000) 1 prefetching on, but conservative (default at -03 when prefetch is on) 2 prefetching on, and aggressive | |
| C*$* PREFETCH_MANUAL, #pragma prefetch_manual | |
Specify whether manual prefetches (through pragmas) should be respected or ignored. Scope: entire function containing the pragma. 0 ignore manual prefetches (default for all processors except R10000 and R12000) 1 respect manual prefetches (default at -03 for R10000 and beyond) | |
| C*$* PREFETCH_REF, #pragma prefetch_ref | |
The object specified is the reference itself; for example, an array element A(i, j). The object can also be a scalar, for example, x, an integer. Must be specified. A specified stride prefetches every stride iterations of this loop. Optional; the default is 1. The specified level specifies the level in memory hierarchy to prefetch. Optional; the default is 2. lev=1: prefetch from L2 to L1 cache. lev=2: prefetch from memory to L1 cache. kind specifies read/write. Optional; the default is write. size specifies the size (in Kbytes) of this object referenced in this loop. Must be a constant. Optional. | |
The effect of this pragma is:
Generate a prefetch and connect to the specified reference (if possible).
Search for array references that match the supplied reference in the current loop-nest. If such a reference is found, then that reference is connected to this prefetch node with the specified latency. If no such reference is found, then this prefetch node stays free-floating and is scheduled “loosely.”
Ignore all references to this array in this loop-nest by the automatic prefetcher (if enabled).
If the size is specified, then the auto-prefetcher (if enabled) uses that number in its volume analysis for this array.
No scope, just generate a prefetch.
The following pragmas and/or directives control fill and/or alignment of symbols. This section uses the term pragma when describing either a pragma or a directive.
The align_symbol pragma aligns the start of the named symbol at the specified alignment. The fill_symbol pragma pads the named symbol.
| C*$* FILL_SYMBOL, #pragma fill_symbol, C*$* ALIGN_SYMBOL, #pragma align_symbol | ||
The fill_symbol/align_symbol pragmas take a symbol, that is, a variable that is a Fortran COMMON , a C/C++ global, or an automatic variable (but not a formal and not an element of a structured type like a struct or an array). The second argument in the pragma may be one of the keywords:
The align_symbol pragma aligns the start of the named symbol at the specified alignment, that is, the symbol “s” will start at the specified alignment boundary. The fill_symbol pragma pads the named symbol with additional storage so that the symbol is assured not to overlap with any other data item within the storage of the specified size. The additional padding required is heuristically divided between each end of the specified variable. For instance, a fill_symbol pragma for the L1cacheline guarantees that the specified symbol does not suffer from false-sharing for the L1 cache line. For global variables, these pragmas must be specified at the variable definition, and are optional at the declarations of the variable. For COMMON block variables, these pragmas are required at each declaration of the COMMON block. Since the pragmas modify the allocated storage and its alignment for the named symbol, inconsistent pragmas can lead to undefined results. The align_symbol pragma is ineffective for local variables of fixed-size symbols, such as simple scalars or arrays of known size. The pragma continues to be effective for stack-allocated arrays of dynamically determined size. A variable cannot have both fill_symbol and align_symbol pragmas applied to it. Examples:
| ||
The following pragmas/directives control dependence analysis.
| CDIR$ IVDEP, #pragma ivdep | |||||||
Liberalize dependence analysis. This applies only to inner loops. Given two memory references, where at least one is loop variant, ignore any loop-carried dependences between the two references. For example:
ivdep does not break the dependence since b(k) is not loop variant.
ivdep does break the dependence, but the compiler warns the user that it is breaking an obvious dependence.
ivdep does break the dependence.
ivdep does not break the dependence on a(i) since it is within an iteration. If -OPT:cray_ivdep=TRUE, use Cray semantics. Break all lexically backward dependences. For example:
ivdep does break the dependence but the compiler warns the user that it is breaking an obvious dependence.
ivdep does not break the dependence since the dependence is from the load to the store, and the load comes lexically before the store. To break all dependencies, specify -OPT:liberal_ivdep=TRUE . -OPT:cray_ivdep and -OPT:liberal_ivdep are OFF (FALSE) by default. | |||||||
Floating-point numbers (the Fortran REAL* n, DOUBLE PRECISION, and COMPLEX* n, and the C float, double, and long double) are inexact representations of ideal real numbers. The operations performed on them are also necessarily inexact. However, the MIPS processors conform to the IEEE 754 floating-point standard, producing results as precise as possible given the constraints of the IEEE 754 representations, and the MIPSpro compilers generally preserve this conformance. Note, however, that 128-bit floating point (that is, the Fortran REAL*16 and the C long double) is not precisely IEEE-compliant. In addition, the source language standards imply rules about how expressions are evaluated.
Most code that has not been written with careful attention to floating-point behavior does not require precise conformance to either the source language expression evaluation standards or to IEEE 754 arithmetic standards. Therefore, the MIPSpro compilers provide a number of options that trade off source language expression evaluation rules and IEEE 754 conformance against better performance of generated code. These options allow transformations of calculations specified by the source code that may not produce precisely the same floating point result, although they involve a mathematically equivalent calculation.
Two of these options are the preferred controls:
-OPT:roundoff=n deals with the extent to which language expression evaluation rules are observed, generally affecting the transformation of expressions involving multiple operations.
-OPT:IEEE_arithmetic=n deals with the extent to which the generated code conforms to IEEE 754 standards for discrete IEEE-specified operations (for example, a divide or a square root).
The -OPT:roundoff option provides control over floating point accuracy and overflow/underflow exception behavior relative to the source language rules.
The roundoff option specifies the extent to that optimizations are allowed to affect floating point results, in terms of both accuracy and overflow/underflow behavior. The roundoff value, n, has a value in the range 0-3. Roundoff values are described in the following list:
| roundoff=0 | |
Do no transformations that could affect floating-point results. This is the default for optimization levels -O0 to -O2. | |
| roundoff=1 | |
Allow transformations with limited effects on floating point results. For roundoff, limited means that only the last bit or two of the mantissa is affected. For overflow (or underfow), it means that intermediate results of the transformed calculation may overflow within a factor of two of where the original expression may have overflowed (or underflowed). Note that effects may be less limited when compounded by multiple transformations. | |
| roundoff=2 | |
Allow transformations with more extensive effects on floating point results. Allow associative rearrangement, even across loop iterations, and distribution of multiplication over addition or subtraction. Disallow only transformations known to cause cumulative roundoff errors, or overflow or underflow, for operands in a large range of valid floating-point values. Reassociation can have a substantial effect on the performance of software pipelined loops by breaking recurrences. This is therefore the default for optimization level -O3. | |
| roundoff=3 | |
Allow any mathematically valid transformation of floating point expressions. This allows floating point induction variables in loops, even when they are known to cause cumulative roundoff errors, and fast algorithms for complex absolute value and divide, which overflow (underflow) for operands beyond the square root of the representable extremes. | |
The -OPT:IEEE_arithmetic option controls conformance to IEEE 754 arithmetic standards for discrete operators.
The -OPT:IEEE_arithmetic option specifies the extent to which optimizations must preserve IEEE floating-point arithmetic. The value n must be in the range of 1 through 3. Values are described in the following list:
| -OPT:IEEE_arithmetic=1 | |
No degradation: do no transformations that degrade floating-point accuracy from IEEE requirements. The generated code may use instructions such as madd, which provides greater accuracy than required by IEEE 754. This is the default. | |
| -OPT:IEEE_arithmetic=2 | |
Minor degradation: allow transformations with limited effects on floating point results, as long as exact results remain exact. This option allows use of the MIPS4 recip and rsqrt operations. | |
| -OPT:IEEE_arithmetic=3 | |
Conformance not required: allow any mathematically valid transformations. For instance, this allows implementation of x/y as x*recip(y), or sqrt(x) as x*rsqrt(x) . | |
As an example, consider optimizing the following Fortran code fragment:
INTEGER i, n
REAL sum, divisor, a(n)
sum = 0.0
DO i = 1,n
sum = sum + a(i)/divisor
END DO |
At roundoff=0 and IEEE_arithmetic=1, the generated code must do the n loop iterations in order, with a divide and an add in each.
Using IEEE_arithmetic=3, the divide can be treated like a(i)*(1.0/divisor). For example, on the MIPS R8000 and R10000, the reciprocal can be done with a recip instruction. But more importantly, the reciprocal can be calculated once before the loop is entered, reducing the loop body to a much faster multiply and add per iteration, which can be a single madd instruction on the R8000 and R10000.
Using roundoff=2, the loop may be reordered. For example, the original loop takes at least 4 cycles per iteration on the R8000 (the latency of the add or madd instruction). Reordering allows the calculation of several partial sums in parallel, adding them together after loop exit. With software pipelining, a throughput of nearly 2 iterations per cycle is possible on the R8000, a factor of 8 improvement.
Consider another example:
INTEGER i,n
COMPLEX c(n)
REAL r
DO i = 1,n
r = 0.1 * i
c(i) = CABS ( CMPLX(r,r) )
END DO |
Mathematically, r can be calculated by initializing it to 0.0 before entering the loop and adding 0.1 on each iteration. But doing so causes significant cumulative errors because the representation of 0.1 is not exact. The complex absolute value is mathematically equal to SQRT(r*r + r*r). However, calculating it this way causes an overflow if 2*r*r is greater than the maximum REAL value, even though a representable result can be calculated for a much wider range of values of r (at greater cost). Both of these transformations are forbidden for roundoff=2, but enabled for roundoff=3.
Other options exist that allow finer control of floating point behavior than is provided by -OPT:roundoff. The options may be used to obtain finer control, but they may disappear or change in future compiler releases.
The preceding options can change the results of floating point calculations, causing less accuracy (especially -OPT:IEEE_arithmetic), different results due to expression rearrangement (-OPT:roundoff ), or NaN/Inf results in new cases. Note that in some such cases, the new results may not be worse (that is, less accurate) than the old, they just may be different. For instance, doing a sum reduction by adding the terms in a different order is likely to produce a different result. Typically, that result is not less accurate, unless the original order was carefully chosen to minimize roundoff.
If you encounter such effects when using these options (including -O3, which enables -OPT:roundoff=2 by default), first attempt to identify the cause by forcing the safe levels of the options: -OPT:IEEE_arithmetic=1:roundoff=0. When you do this, do not have the following options explicitly enabled:
| -OPT:div_split |
| -OPT:fast_complex |
| -OPT:fast_exp |
| -OPT:fast_sqrt |
| -OPT:fold_reassociate |
| -OPT:recip |
| -OPT:rsqrt |
If using the safe levels works, you can either use the safe levels or, if you are dealing with performance-critical code, you can use the more specific options (for example, div_split, fast_complex , and so forth) to selectively disable optimizations. Then you can identify the source code that is sensitive and eliminate the problem. Or, you can avoid the problematic optimizations.
The following -OPT options allow control over a variety of optimizations. These include:
| -OPT:Olimit | |
This option controls the size of procedures to be optimized. Procedures above the cutoff limit are not optimized. A value of 0 means “infinite Olimit,” and causes all procedures to be optimized. If you compile at -O2 or above, and a routine is so large that the compile speed may be slow, then the compiler prints a message telling you the Olimit value needed to optimize your program. | |
The following -OPT options perform algebraic simplifications of expressions, such as turning x + 0 into x.
| -OPT:fold_unsafe_relops | |
Controls folding of relational operators in the presence of possible integer overflow. On by default. For example, X + Y < 0 may turn into X < Y. If X + Y overflows, it is possible to get different answers. | |
| -OPT:fold_unsigned_relops | |
Determines if simplifications are performed of unsigned relational operations that may result in wrong answers in the event of integer overflow. Off by default. The example is the same as above, only for unsigned integers. | |
The #pragma mips_frequency_hint provides information about execution frequency for certain regions in the code. The format of the pragma is:
#pragma mips_frequency_hint {NEVER| INIT} [function_name]
You can provide the following indications: NEVER or INIT.
NEVER: This region of code is never or rarely executed. The compiler may move this region of the code away from the normal path. This movement may either be to the end of the procedure or at some point to an entirely separate section.
INIT: This region of code is executed only during initialization or startup of the program. The compiler may try to put all regions under INIT together to provide better locality during the startup of a program.
You can specify this pragma in two ways:
You can specify it with a function declaration. It then applies everywhere the function is called. For example:
extern void Error_Routine (); #pragma mips_frequency_hint NEVER Error_Routine
| Note: The pragma must appear after the function declaration. |
You can place the pragma anywhere in the body of a procedure. It then applies to the next statement that follows the pragma. For example:
if (some_condition) { #pragma mips_frequency_hint NEVER Error_Routine (); }
This section describes the part of the compiler that generates code.
The code generator processes an input program unit (PU) in intermediate representation form to produce an output object file (.o) or assembly file (.s).
Program units are partitioned into basic blocks. A new basic block is started at each branch target. Basic blocks are also ended by CALL statements or branches. Large basic blocks are arbitrarily ended after a certain number of operations, because some algorithms in the code generator work on one basic block at a time (“local” algorithms) and have a complexity that is nonlinear in the number of operations in the basic block.
This section covers the following topics:
At optimization levels -O0 and -O1, the code generator only uses local algorithms that operate individually on each basic block. At -O0, no code generator optimization is done. References to global objects are spilled and restored from memory at basic block boundaries. At -O1, the code generator performs standard local optimizations on each basic block (for example, copy propagation, dead code elimination) as well as some elimination of useless memory operations.
At optimization levels -O2 and -O3, the code generator includes global register allocation and a large number of special optimizations for innermost loops, including software pipelining at -O3.
Consider the Fortran statement, a(i) = b(i). At -O0, the value of i is kept in memory and is loaded before each use. This statement uses two loads of i. The code generator local optimizer replaces the second load of i with a copy of the first load, and then it uses copy-propagation and dead code removal to eliminate the copy. Comparing .s files for the -O0 and -O1 versions shows:
The .s file for -O0:
lw $3,20($sp) # load address of i lw $3,0($3) # load i addiu $3,$3,-1 # i - 1 sll $3,$3,3 # 8 * (i-1) lw $4,12($sp) # load base address for b addu $3,$3,$4 # address for b(i) ldc1 $f0,0($3) # load b lw $1,20($sp) # load address of i lw $1,0($1) # load i addiu $1,$1,-1 # i - 1 sll $1,$1,3 # 8 * (i-1) lw $2,4($sp) # load base address for a addu $1,$1,$2 # address for a(i) sdc1 $f0,0($1) # store a |
The .s file for -O1:
lw $1,0($6) # load i lw $4,12($sp) # load base address for b addiu $3,$1,-1 # i - 1 sll $3,$3,3 # 8 * (i-1) lw $2,4($sp) # load base address for a addu $3,$3,$4 # address for b(i) addiu $1,$1,-1 # i - 1 ldc1 $f0,0($3) # load b sll $1,$1,3 # 8 * (i-1) addu $1,$1,$2 # address for a(i) sdc1 $f0,0($1) # store a |
The .s file for -O2 (using OPT to perform scalar optimization) produces optimized code:
lw $1,0($6) # load i sll $1,$1,3 # 8 * i addu $2,$1,$5 # address of b(i+1) ldc1 $f0,-8($2) # load b(i) addu $1,$1,$4 # address of a(i+1) sdc1 $f0,-8($1) # store a(i) |
This section provides additional information about the -O2 and -O3 optimization levels.
The if conversion transformation converts control-flow into conditional assignments. For example, consider the following code before if conversion. Note that expr1 and expr2 are arbitrary expressions without calls or possible side effects. For example, if expr1 is i++, the following example would be wrong because ` i' would not be updated.
if ( cond )
a = expr1;
else
a = expr2; |
After if conversion, the code looks like this:
tmp1 = expr1; tmp2 = expr2; a = (cond) ? tmp1 : tmp2; |
Performing if conversion results in the following benefits:
It exposes more instruction-level parallelism. This is almost always valuable on hardware platforms such as R10000.
It eliminates branches. Some platforms (for example, the R10000) have a penalty for taken branches. There can be substantial costs associated with branches that are not correctly predicted by branch prediction hardware. For example, a mispredicted branch on R10000 has an average cost of about 8 cycles.
It enables other compiler optimizations. Currently, cross-iteration optimizations and software pipelining both require single basic block loops. The if conversion changes multiple basic block innermost loops into single basic block innermost loops.
In the preceding code that was if converted, the expressions, expr1 and expr2, are unconditionally evaluated. This can conceivably result in the generation of exceptions that do not occur without if conversion. An operation that is conditionalized in the source, but is unconditionally executed in the object, is called a speculated operation. Even if the -TENV:X level prohibits speculating an operation, it may be possible to if convert. For information about the -TENV option, see the appropriate compiler man page.
For example, suppose expr1 = x + y; is a floating point add, and X=1. Speculating FLOPs is not allowed (to avoid false overflow exceptions). Define x_safe and y_safe by x_safe = (cond)? x : 1.0; y_safe = (cond) ? y : 1.0;. Then unconditionally evaluating tmp1 = x_safe + y_safe; cannot generate any spurious exception. Similarly, if X < 4, and expr1 contains a load (for example, expr1 = *p), it is illegal to speculate the dereference of p. But, defining p_safe = (cond) ? p : known_safe_address; and then tmp1 = *p_safe; cannot generate a spurious memory exception.
Notice that with -TENV:X=2, it is legal to speculate FLOPs, but not legal to speculate memory references. So expr1 = *p + y; can be speculated to tmp1 = *p_safe + y;. If *known_safe_address is uninitialized, there can be spurious floating point exceptions associated with this code. In particular, on some MIPS platforms (for example, R10000) if the input to a FLOP is a denormalized number, then a trap will occur. Therefore, by default, the code generator initializes *known_safe_address to 1.0.
Four main types of cross-iteration optimizations include:
Read-Read Elimination: Consider the following example:
DO i = 1,n B(i) = A(i+1) - A(i) END DO
The load of A(i+1) in iteration i can be reused (in the role of A(i)) in iteration i+1. This reduces the memory requirements of the loop from 3 references per iteration to 2 references per iteration.
Read-Write Elimination: Sometimes a value written in one iteration is read in a later iteration. For example:
DO i = 1,n B(i+1) = A(i+1) - A(i) C(i) = B(i) END DO
In this example, the load of B(i) can be eliminated by reusing the value that was stored to B in the previous iteration.
Write-Write Elimination: Consider the following example:
DO i = 1,n B(i+1) = A(i+1) - A(i) B(i) = C(i) - B(i) END DO
Each element of B is written twice. Only the second write is required, assuming read-write elimination is done.
Common Sub-Expression Elimination: Consider the following example:
DO i = 1,n B(i) = A(i+1) - A(i) C(i) = A(i+2) - A(i+1) END DO
The value computed for C in iteration i may be used for B in iteration i+1 . Thus only one subtract per iteration is required.
In this example, unrolling 4 times converts this code:
for( i = 0; i < n; i++ ) {
a[i] = b[i];
} |
to this code:
for ( i = 0; i < (n % 4); i++ ) {
a[i] = b[i];
}
for ( j = 0; j < (n / 4); j++ ) {
a[i+0] = b[i+0];
a[i+1] = b[i+1];
a[i+2] = b[i+2];
a[i+3] = b[i+3];
i += 4;
} |
Loop unrolling:
Exposes more instruction-level parallelism. This may be valuable even on execution platforms such as R10000 or R12000 systems.
Eliminates branches.
Amortizes loop overhead. For example, unrolling replaces four increments i+=1 with one increment i+=4.
Enables some cross-iteration optimizations such as read/write elimination over the unrolled iterations.
Recurrence breaking offers multiple benefits. Before the recurrences are broken (see both of the following examples), the compiler waits for the prior iteration's add to complete (four cycles on the R8000) before starting the next one, so four cycles per iteration occur.
When the compiler interleaves the reduction, each add must still wait for the prior iteration's add to complete, but four of these are done at one time, then partial sums are combined on exiting the loop. The four iterations are done in four cycles, or one cycle per iteration, quadruple the speed.
With back substitution, each iteration depends on the result from two iterations back (not the prior iteration), so four cycles per two iterations occur, or two cycles per iteration (double the speed).
| Note: The compiler actually interleaves and back-substitutes these examples even more than shown below, for even greater benefit (3 cycles/4 iterations for the R8000 in both cases). These examples are simple for purposes of exposition. |
Two types of recurrence breaking are reduction interleaving and back substitution:
Reduction interleaving. For example, interleaving by 4 transforms this code:
sum = 0 DO i = 1,n sum = sum + A(i) END DO
After reduction interleaving, the code looks like this (omitting the cleanup code):
sum1 = 0 sum2 = 0 sum3 = 0 sum4 = 0 DO i = 1,n,4 sum1 = sum1 + A(i+0) sum2 = sum2 + A(i+1) sum3 = sum3 + A(i+2) sum4 = sum4 + A(i+3) END DO sum = sum1 + sum2 + sum3 + sum4
Back substitution. For example:
DO i = 1,n B(i+1) = B(i) + k END DO
The code is converted to:
k2 = k + k B(2) = B(1) + k DO i = 2,n B(i+1) = B(i-1) + k2 END DO
Software pipelining schedules innermost loops to keep the hardware pipeline full. For information about software pipelining, see the MIPSpro 64-Bit Porting and Transition Guide. Also, for a general discussion of instruction level parallelism, refer to B.R.Rau and J.A.Fisher, “Instruction Level Parallelism,” Kluwer Academic Publishers, 1993 (reprinted from the Journal of Supercomputing, Volume 7, Number 1/2).
The global code motion phase performs various code motion transformations in order to reduce the overall execution time of a program. The global code motion phase is useful because it does the following:
It moves instructions in nonloop code. In the following code example, assume expr1 and expr2 are arbitrary expressions that cannot be if-converted. The cond is a Boolean expression that evaluates to either true or false and has no side effects with either expr1 or expr2.
if (cond) a = expr1; else a = expr2;After global code motion, the code looks like this:
a = expr1; if (!cond) a = expr2;Note, that expr1 is arbitrarily chosen to speculate above the branch. The decision to select candidates for code movement are based on several factors, including resource availability, critical length, basic block characteristics, and so forth.
It moves instructions in loops with control-flow. In the following code example, assume that p is a pointer and expr1 and expr2 are arbitrary expressions involving p. Also, assume that cond is a Boolean expression that uses p and has no side effects with expr2 and expr1.
while (p != NULL) { if (cond) sum += expr1(p); else sum += expr2(p); p = p->next; }After global code motion, the code looks like this:
while (p != NULL) { t1 = expr1(p); t2 = expr2(p); if (cond) sum += t1; else sum += t2; p = p->next; }Note, that t1 and t2 temporaries are created to evaluate the respective expressions and conditionally executed. The increment of the pointer, p=p->next, cannot move above the branch because of side effects with the condition.
It moves instructions across procedure calls. In the following code example, assume that expr1 has no side effects with the procedure call to foo (that is, procedure foo does not use and/or modify the expression expr1).
... foo(); expr1; ...
After global code motion, the code looks like this:
... expr1; foo(); ...
The benefits of global code motion include the following:
It exposes more instruction-level parallelism. Global code motion identifies regions and/or blocks that have excessive and/or insufficient parallelism than that provided by the target architecture. Global code motion effectively redistributes (or load balances) the regions/blocks by selectively performing code movements between them. This can effectively reduce their respective schedule lengths and the overall execution time of the program.
It provides branch delay slot filling. Global code motion fills branch delay slots and converts most frequently executed branches to branch-likely form (for example, beql, rs, rt, L1).
It enables other compiler optimizations. As a result of performing global code motion, some branches are either removed or transformed to a more effective form.
The steps performed by the code generator at -O2 and -O3 include:
Nonloop if conversion. This also works in loops by performing any if-conversion that produces faster code.
Find innermost loop candidates for further optimization. Loops are rejected for any of the following reasons:
Marked UNIMPORTANT (for example, LNO cleanup loop)
Strange control flow (for example, branch into the middle)
if convert (-O3 only). This transforms a multi-basic block loop into a single basic block containing operations with “guards.” The if conversion of loop bodies containing branches can fail for any of the following reasons:
Cross-iteration read/write (read/read, and write/write) elimination
Cross-iteration CSE (common subexpression elimination)
Recurrence fixing
Software pipelining
Perform cross-iteration optimizations (except write/write elimination on loops without trip counts; for example, most “while” loops).
Unroll loops.
Fix recurrences.
If still a loop, and there is a trip count, and -O3, invoke software pipelining.
If not software pipelined, reverse if convert.
Reorder basic blocks to minimize (dynamically) the number of taken branches. Also eliminate branches to branches when possible, and remove unreachable basic blocks. This step also happens at -O1 .
Invoke global code motion phase.
At several points in this process local optimizations are performed, since many of the transformations performed can expose additional opportunities. It is also important to note that many transformations require legality checks that depend on alias information. There are three sources of alias information:
At -O3, the loop nest optimizer, LNO, provides a dependence graph for each innermost loop.
The scalar optimizer provides information on aliasing at the level of symbols. That is, it can tell whether arrays A and B are independent, but it does not have information about the relationship of different references to a single array.
The code generator can sometimes tell that two memory references are identical or distinct. For example, if two references use the same register, and there are no definitions of that register between the two references, then the two references are identical.
The code generator makes many choices, for example, what conditional constructs to if convert, or how much to unroll a loop. In most cases, the compiler makes reasonable decisions. Occasionally, however, you can improve performance by modifying the default behavior.
You can control the code generator by:
Increasing or decreasing the unroll amount.
A heuristic is controlled by -OPT:unroll_analysis (on by default), which generally tries to minimize unrolling. Less unrolling leads to smaller code size and faster compilation. You can change the upper bound for the amount of unrolling with -OPT:unroll_times (default is 8) or -OPT:unroll_size (the number of instructions in the unrolled body, current default is 80).
You can look at the .s file for notes (starting with #<loop>) that indicate how the decision to limit unrolling was made. For example, loops are not unrolled with recurrences that cannot be broken (since unrolling cannot possibly help in these cases), so the .s file now tells why unrolling was limited and how to change it. For example:
#<loop> Loop body line 7, nesting depth:1, estimated iterations: 100 #<loop> Not unrolled: limited by recurrence of 4 cycles #<loop> Not unrolled: disable analysis w/-CG:unroll_analysis=off
Disabling software pipelining with -OPT:swp=off.
As far as the code generator is concerned, -O3 -OPT:swp=off is the same as -O2. Since LNO does not run at -O2, however, the input to the code generator can be very different, and the available aliasing information can be very different. In particular, cross-iteration loop optimizations are much more effective at -O3 even with -OPT:swp=off, due to the improved alias information.
This section explains a few miscellaneous topics including:
Prefetch and Load Latency
Frequency and Feedback
At the -O3 level of optimization, with -r10000, LNO generates prefetches for memory references that are likely to miss either the L1 (primary) or the L2 (secondary) cache. The code generator generates prefetch operations for L2 prefetches, and implements L1 prefetches as follows: makes sure that loads that had associated L1 prefetches are issued at least 8 cycles before their results are used.
It is often possible to reduce prefetch overhead by eliminating some of the corresponding prefetches from different replications. For example, suppose a prefetch is only required on every fourth iteration of a loop, because four consecutive iterations will load from the same cache line. If the loop is replicated four times by software pipelining, then there is no need for a prefetch in each replication, so three of the four corresponding prefetches are pruned away.
The original software pipelining schedule has room for a prefetch in each replication, and the number of cycles for this schedule is what is described in the software pipelining notes as “cycles per iteration.” The number of memory references listed in the software pipelining notes (“mem refs”) is the number of memory references including prefetches in Replication 0. If some of the prefetches have been pruned away from replication 0, the notes will overstate the number of cycles per iteration while understating the number of memory references per iteration.
Some choices that the code generator makes are decided based on information about the frequency with which different basic blocks are executed. By default, the code generator makes guesses about these frequencies based on the program structure. This information is available in the .s file. The frequency printed for each block is the predicted number of times that block will be executed each time the PU is entered.
The frequency guesses are replaced with the measured frequencies. Currently the information guides if-conversion, some loop unrolling decisions (unrelated to the trip count estimate), global code motion, control flow optimizations, global spill and restore placement, global register allocation, instruction alignment, and delay slot filling. Average loop trip-counts can be derived from feedback information. Trip count estimates are used to guide decisions about how much to unroll and whether or not to software pipeline.
Cording is an optimization technique for reordering parts of your program to achieve better locality of reference and reduce instruction fetch overhead based on dynamically collected data. The following areas are influenced by code region reordering:
Both of these events contribute to instruction fetch overhead, which can be alleviated with better locality of reference. Retrieving an instruction from cache is always faster than retrieving it from memory; so the idea is to keep instructions in cache as much as possible. The frequencies and costs associated with each of those events differ significantly. The size of the program in memory and text-resident set sizes can also be reduced as a result of cording.
Programs can be reordered using either the cord(1) command (see the following section) or the ld(1) linker command (see “Reordering with ld”). The SpeedShop prof(1) command and the WorkShop cvperf(1) user interface are alternative methods of provided feedback files to cord and ld (see “Using prof or cvperf”).
Use the following procedure to optimize your application by reordering its text areas with the cord(1) command:
Run one or more SpeedShop bbcounts experiments to collect performance data, setting caliper points to better identify phases of execution.
% ssrun -bbcounts a.out
Use sswsextr to extract working set files related to the interval between each pair of calipers in the experiment file.
% sswsextr a.out a.out.bbcounts.m20683
A working set list file (in this case, a.out.a.out.bbcounts.m20683.wslist ) is also generated. It assigns a number to the working set files and the weight for each one (the default weight is 1).
Use ssorder(1) or sscord(1) to generate a cord feedback file combining the working set files for the binary.
% ssorder -wsl a.out.a.out.bbcounts.m20683.wslist -gray -o a.out.fb a.out
% sscord -wsl a.out.a.out.bbcounts.m20683.wslist a.out
Use the cord command to reorder the procedures in the binary.
% cord a.out a.out.fb
The following procedure uses the ld linker to reorder routines in a source file. The procedure shows how to reorder routines in an executable file (a.out), but you can also reorder a DSO.
Compile the application as follows:
% f90 -OPT:procedure_reorder verge.f
You can turn reordering on or off for a given compilation by setting the procedure_reorder argument to an optional Boolean value. Doing so is convenient if you are compiling the application in a makefile. Setting a Boolean value of 1 enables reordering, while a value of 0 disables reordering.
% f90 -OPT:procedure_reorder=1 verge.f
Run a SpeedShop bbcounts experiment to collect performance data, setting caliper points to better identify phases of execution.
% ssrun -bbcounts a.out
Use sswsextr to extract working set files for the binary.
% sswsextr a.out a.out.bbcounts.m20683
Use ssorder or sscord to generate a cord feedback file, combining multiple working set files for the binary.
% ssorder -wsl a.out.a.out.bbcounts.m20683.wslist -gray -o a.out.fb a.out
% sscord -wsl a.out.a.out.bbcounts.m20683.wslist a.out
Use ld to reorder the procedures in the binary as follows:
% ld -LD_LAYOUT:reorder_file=a.out.fb
Once the experiment file is generated, you can generate a cord feedback file using either the SpeedShop prof command or the WorkShop cvperf user interface.
Enter the prof command as follows:
% prof -cordfb a.out.bbcounts.m20683 |
The -cordfb option generates cord feedback for the executable and all DSOs. Along with its usual output, this command writes a cord feedback file named a.out.fb.
While using prof will give you what you want, using either the ssorder or sscord method described in the previous subsections or the cvperf method described in the following paragraphs produces more efficient results.
If you are using the WorkShop performance analyzer, first enter the cvperf command with the experiment file as an argument:
% cvperf a.out.bbcounts.m20683 |
Select the Working Set View from the Views menu. Once the new window appears, choose Save Cord Map File from the Admin menu. By default, the name of the cord feedback file will be a.out.fb.
Specify the cord feedback file on the cord or ld commands to reorder the procedures in the binary:
% cord a.out a.out.fb % ld -LD_LAYOUT:reorder_file=a.out.fb |
The global (scalar) optimizer is part of the compiler back end. It improves the performance of object programs by transforming existing code into more efficient coding sequences. The optimizer distinguishes between C, C++, and Fortran programs to take advantage of the various language semantics.
This section describes the global optimizer and contains coding hints. Specifically this section includes:
Hints for Writing Programs
Coding Hints for Improving Other Optimization
Using SpeedShop to optimize your code.
Use the following hints when writing your programs:
Do not use indirect calls (that is, calls via function pointers, including those passed as subprogram arguments). Indirect calls may cause unknown side effects (for instance, changing global variables) that reduce the amount of optimization possible.
Use functions that return values instead of pointer parameters.
Avoid unions that cause overlap between integer and floating point data types. The optimizer cannot assign such fields to registers.
Use local variables and avoid global variables. In C and C++ programs, declare any variable outside of a function as static, unless that variable is referenced by another source file. Minimizing the use of global variables increases optimization opportunities for the compiler.
Declare pointer parameters as const in prototypes whenever possible, that is, when there is no path through the routine that modifies the pointee. This allows the compiler to avoid some of the negative assumptions normally required for pointer and reference parameters (see the following).
Pass parameters by value instead of passing by reference (pointers) or using global variables. Reference parameters have the same performance-degrading effects as the use of pointers.
Aliases occur when there are multiple ways to reference the same data object. For instance, when the address of a global variable is passed as a subprogram argument, it may be referenced either using its global name, or via the pointer. The compiler must be conservative when dealing with objects that may be aliased, for instance keeping them in memory instead of in registers, and carefully retaining the original source program order for possibly aliased references.
Pointers in particular tend to cause aliasing problems, since it is often impossible for the compiler to identify their target objects. Therefore, you can help the compiler avoid possible aliases by introducing local variables to store the values obtained from dereferenced pointers. Indirect operations and calls affect dereferenced values, but do not affect local variables. Therefore, local variables can be kept in registers. The following example shows how the proper placement of pointers and the elimination of aliasing produces better code.
In the following example, the optimizer does not know if *p++ = 0 will eventually modify len. Therefore, the compiler cannot place len in a register for optimal performance. Instead, the compiler must load it from memory on each pass through the loop.
int len = 10; void zero(char *p) { int i; for (i= 0; i!= len; i++) *p++ = 0; }Increase the efficiency of this example by not using global or common variables to store unchanging values.
Use local variables. Using local (automatic) variables or formal arguments instead of static or global prevents aliasing and allows the compiler to allocated them in registers.
For example, in the following code fragment, the variables loc and form are likely to be more efficient than ext* and stat*.
extern int ext1; static int stat1; void p ( int form ) { extern int ext2; static int stat2; int loc; ... }Write straightforward code. For example, do not use ++ and - - operators within an expression. Using these operators produces side-effects (requires the use of extra temporaries, which increases register pressure).
Avoid taking and passing addresses (and values). Using addresses creates aliases, makes the optimizer store variables from registers to their home storage locations, and significantly reduces optimization opportunities that would otherwise be performed by the compiler.
Avoid functions that take a variable number of arguments. The optimizer saves all parameter registers on entry to VARARG or STDARG functions. If you must use these functions, use the ANSI standard facilities of stdarg.h. These produce simpler code than the older version of varargs.h
The global optimizer processes programs only when you specify the -O2 or -O3 option at compilation. The code generator phase of the compiler performs certain optimizations. This section has coding hints that increase optimization for other passes of the compiler.
In your programs, use tables rather than if-then-else or switch statements. For example, consider this code:
typedef enum { BLUE, GREEN, RED, NCOLORS } COLOR; |
Instead of:
switch ( c ) {
case CASE0: x = 5; break;
case CASE1: x = 10; break;
case CASE2: x = 1; break;
} |
Use:
static int Mapping[NCOLORS] = { 5, 10, 1 };
...
x = Mapping[c]; |
As an optimizing technique, the compiler puts the first eight parameters of a parameter list into registers where they may remain during execution of the called routine. Therefore, always declare, as the first eight parameters, those variables that are most frequently manipulated in the called routine.
Use 32-bit or 64-bit scalar variables instead of smaller ones. This practice can take more data space. However, it produces more efficient code because the MIPS instruction set is optimized for 32-bit and 64-bit data.
The following suggestions apply to C and C++ programs:
Rely on libc.so functions (for example, strcpy, strlen, strcmp, bcopy, bzero, memset, and memcpy). These functions are carefully coded for efficiency.
Use a signed data type, or cast to a signed data type, for any variable that does not require the full unsigned range and must be converted to floating-point. For example:
double d; unsigned int u; int i; /* fast */ d = i; /* fast */ d = (int)u; /* slow */ d = u;
Converting an unsigned type to floating-point takes significantly longer than converting signed types to floating-point; additional software support must be generated in the instruction stream for the former case.
Use signed int types in 64-bit code if they may appear in mixed type expressions with long ints (or with long long int types in either 32-bit or 64-bit code). Since the hardware automatically sign-extends the results of most 32-bit operations, this may avoid explicit zero-extension code. For example:
unsigned int ui; signed int i; long int li; /* fast */ li += i; /* fast */ li += (int)ui; /* slow */ li += ui;
Use const and restrict qualifiers. The __restrict keyword tells the compiler to assume that dereferencing the qualified pointer is the only way the program can access the memory pointed to by that pointer. Hence loads and stores through such a pointer are assumed not to alias with any other loads and stores in the program, except other loads and stores through the same pointer variable. For example:
float x[ARRAY_SIZE]; float *c = x; void f4_opt(int n, float * __restrict a, float * __restrict b) { int i; /* No data dependence across iterations because of __restrict */ for (i = 0; i < n; i++) a[i] = b[i] + c[i]; }
The following suggestions apply to C++ programs:
Use the inline keyword whenever possible. Functions calls in loops that are not inlined prevent loop-nest optimizations and software pipelining.
Use a direct calls rather than indiscriminate use of virtual function calls. The penalty is in method lookup and the inability to inline them.
If your code uses const ref, use -LANG:alias_const when compiling (see “const reference Parameter Optimization with Lang:alias_const”, for more information).
For scalars only, avoid the creation of unnecessary temporaries, that is, Aa = 1 is better than Aa = A(1).
For structs and class, pass by const ref to avoid the overhead of copying.
If your code does not use exception handing, use -LANG:exceptions=off when compiling.
Consider the following example:
extern void pass_by_const_ref(const int& i);
int test(){
//This requires -LANG:alias_const for performance enhancements
int i = 10
int j = 15
pass_by_const_ref(i);
pass_by_const_ref(j);
return i + j;
} |
In the preceding example, the compiler determined that the function pass_by_const_ref does not modify its formal parameter i. That is, the parameter i passed by const reference does not get modified in the function. Consequently the compiler can forward propagate the values of i and j to the return statement, whereas it would otherwise have to reload the values of i and j after the two calls to pass_by_const_ref.
| Note: For this optimization to work correctly, both the caller and the callee have to be compiled with -LANG:alias_const). |
You can legally cast away and modify the const parameter, in the callee which is why the preceding option is not on by default. With this option, the compiler makes an effort to flag warnings about such cases where the callee casts away the const and modifies the parameter. For example:
void f(const int &x) {int *y = (int *) &x; *y = 99;}
int main() {
int z;
f(z); // call to f does modify z; Hence z needs to be reloaded after
the call
return z;
} |
With the preceding example, and -LANG:alias_const, the compiler gives a warning:
Compiling f__GRCi “ex9.C”, line 2 (col. 28): warning(3334): cast to type “int *” may not be safe in presence of -LANG:alias_const. Make sure you are not casting away const to MODIFY the parameter |
If you specify the mutable keyword, then this const optimization is disabled. For example:
class C {
public:
mutable int p;
void f() const { p = 99;} //mutable data member can be modified
// by a const function
int getf() const { return p;}
};
int main() {
C c;
c.f(); // even with -LANG:alias_const, f() can modify c.p
return c.getf();
}; |
SpeedShop is an integrated package of performance tools that you can use to gather performance data and generate reports. To record the experiments, use the ssrun(1) command, which runs the experiment and captures data from an executable (or instrumented version). You can compare experiment results with the sscompare(1) command. To examine data you can use either prof(1) or display the data in the WorkShop graphical user interface with the cvperf(1) command. Speedshop also lets you start a process and attach a debugger to it.
For detailed information about SpeedShop, ssrun, sscompare and prof, see the SpeedShop User's Guide.